



Verificación, p-valores, y Sets de entrenamiento con el Raman portátil Mira P
Esta publicación diferencia entre métodos de identificación de sustancias desconocidas y de verificación de sustancias ya conocidas. El objetivo principal de esta publicación es informar al usuario las capacidades del Raman portátil Mira P de Metrohm. También se pueden encontrar aquí las mejores prácticas para construir sets robustos de entrenamiento para la verificación de materiales con el Raman portátil Mira P.
Introducción
El analizador Raman de Metrohm (Mira P), es un espectrofotómetro Raman portátil diseñado para identificar y verificar sustancias químicas, materiales y productos farmacéuticos de forma rápida y no destructiva. La espectroscopía Raman es una técnica ya establecida para la identificación de sustancias desconocidas por la comparación del espectro de la muestra versus librerías de referencia. Sin embargo, el Mira P tiene una capacidad única de identificación de materiales dentro de la línea Metrohm. Esta publicación describe cómo el análisis estadístico se relaciona con el diseño del experimento y cómo ambos pueden ayudar al usuario a crear modelos robustos para la verificación.
HQI para la identificación de sustancias desconocidas
Para la identificación con el Mira P, una técnica de correlación de Pearson genera un índice de calidad de correlación (Hit Quality Index, HQI por sus siglas en inglés) o R2, el cual es una medida de la similitud del espectro de la muestra versus el presente en la librería de referencia. El valor mostrado varía entre 0 y 1, donde valores cercanos a 1 indican una correlación alta con el espectro presente en la librería. El instrumento genera una lista de compuestos con valores de HQI por encima de un valor umbral, el cual generalmente es 0,85. Este método es: a) fácil de implementar, b) rápido, y c) adecuado para el uso de librerías químicas grandes.
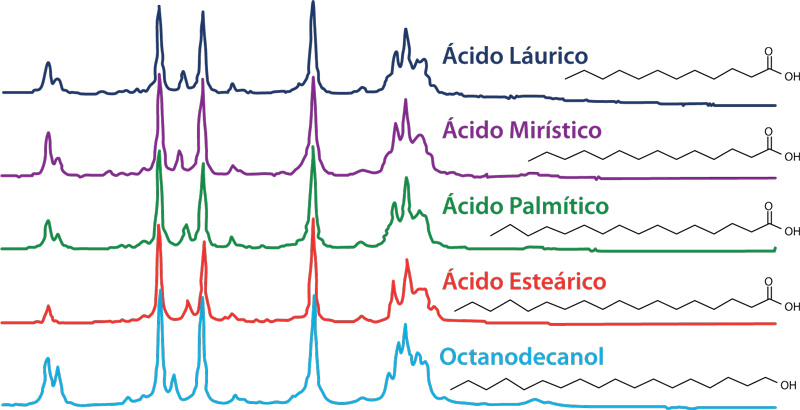
Aunque este método es usado extensamente y es confiable para ciertas aplicaciones, no es adecuado para moléculas que presentan diferencias pequeñas no significativas en el espectro Raman. Por ejemplo, la Figura 2 ilustra los espectros de una familia de compuestos de cuatro ácidos grasos y un alcohol similar, que principalmente difieren en el largo de la cadena carbonada saturada (Figura 1). La similitud espectral es innegable, y refleja el parecido de los compuestos.
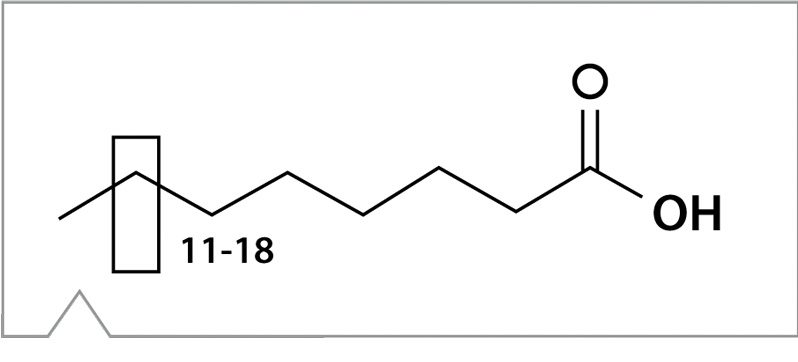
Figura 1. Estructura de los ácidos grasos mostrados en la Figura 2.
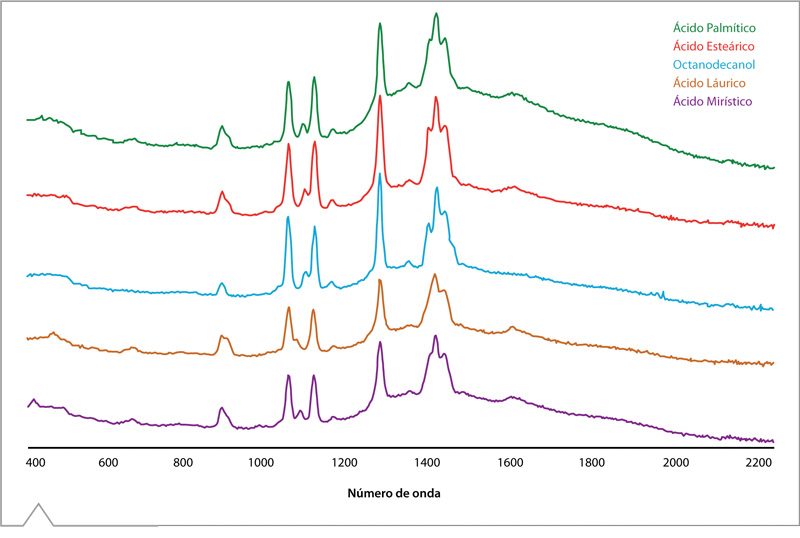
Figura 2. Espectro Raman de los ácidos grasos / alcohol con estructura similar
Valores HQI
Dado que los valores de HQI son una medida de la correlación entre el espectro de referencia y el de la muestra, puede resultar en la identificación errónea de sustancias muy similares. Es decir, el análisis con HQI puede resultar en falsos positivos. Los valores presentados en la Tabla 1 reflejan la similitud de las moléculas y sus espectros son mostrados en las Figuras 2.
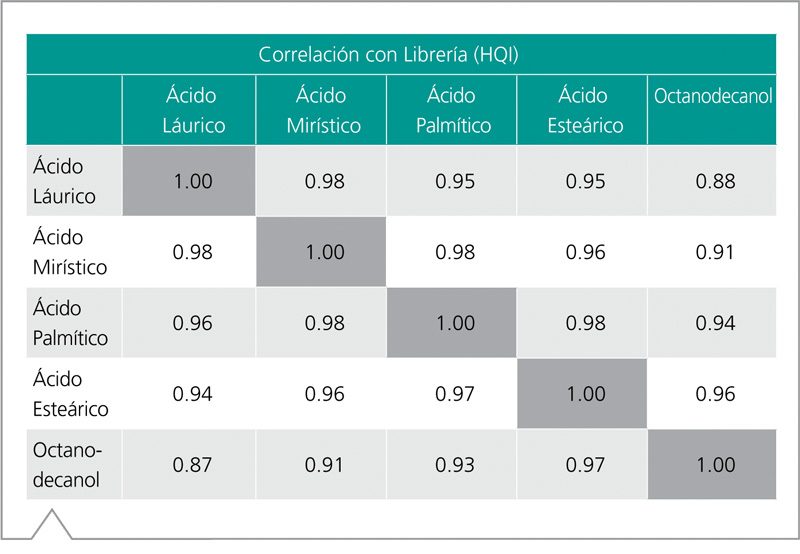
Tabla 1. Correlación de HQI para la familia de ácidos grasos
Cuando cada compuesto de esta familia es comparado con los demás, el valor de HQI obtenido está por encima del límite asignado de 0,85. Como resultado, la diferenciación entre estas sustancias es pobre.
Verificación de muestras con p-valores
El método de verificación debe abordar con éxito este problema. A diferencia de ciertas técnicas de identificación basadas en similitudes entre los espectros, el método de verificación refleja diferencias espectrales. Este método está basado en el Análisis de Componentes Principales (PCA por sus siglas en inglés), un análisis estadístico que reduce un set de datos complejos a características básicas que describen mejor la información, sus “componentes principales”2. Este método transforma espectros altamente correlacionados en un pequeño set de variables ortogonales que pueden ser visualizados como un gráfico de dispersión de puntaje. Por lo tanto, los espectros mostrados en la Figura 2 pueden ser modelados para que describan variaciones dentro y entre compuestos en lugar de similitudes (Figura 3):
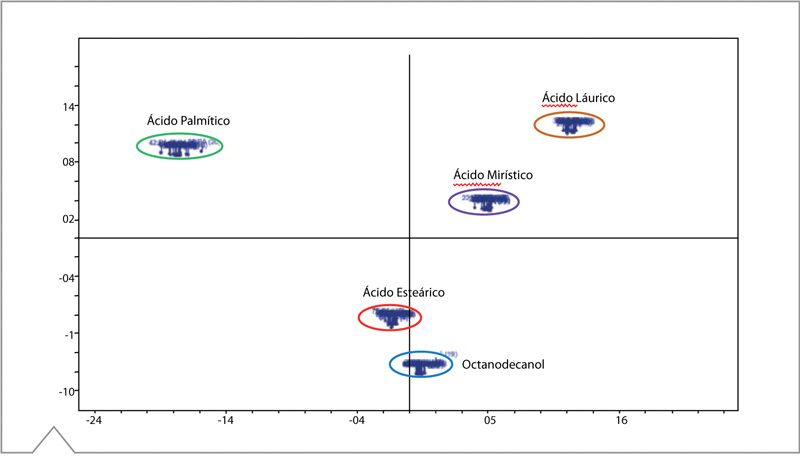
Figura 3. Gráficos de dispersión de PCA representando a la familia de ácidos grasos.
Los diagramas de dispersión PCA, junto con un intervalo de confianza definido, se convierten en los modelos de referencia contra los cuales las muestras en el futuro son comparadas. Cada espectro de muestra es proyectado sobre el modelo PCA para ver qué tan bien encaja en los límites del modelo, los cuales son determinados por el intervalo de confianza.
Intervalos de confianza
Los intervalos de confianza son definidos por un elipsoide T2 de Hotelling (los óvalos por debajo y encima de la Figura 4) y es una forma muy importante de visualizar cuanta varianza es aceptable entre cada grupo4. Por ejemplo, los intervalos de confianza del 90 y 95% han sido proyectados sobre los diagramas mostrados en la Figura 4; ambos son una representación muy buena del set de datos, pero difieren en el nivel de aceptación del modelo. En el ejemplo A, el nivel de confianza del 90% significa que unas pocas muestras serán aceptadas dentro del set de entrenamiento, pero el modelo produce mayores confianzas en la exactitud de los resultados. Un nivel de confianza del 95% mostrado en B ilustra que muestras con un nivel mayor de varianza (distancia al centro = distancia de Mahalonobis) debe ser verificadas como parte del modelo.
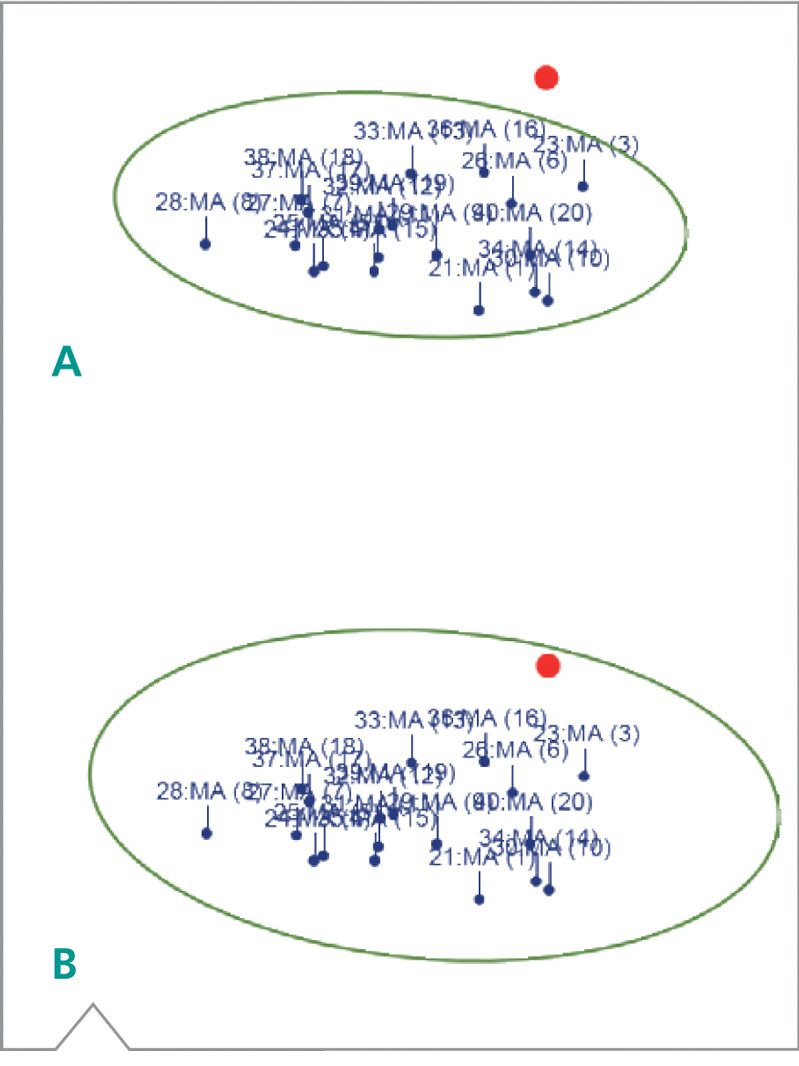
Figura 4. Niveles de confianza representados por elipsoide T2 de Hotelling. A=90%, B=95%.
Testeo de hipótesis y p-valores
Cuando un espectro de prueba es proyectado sobre el espacio del modelo, el resultado es un p-valor: un indicador de cuán bien la muestra encaja entre los límites del modelo a un dado nivel de confianza4. En otras palabras, el p-valor marca la importancia de los resultados cuando un test de hipótesis estadístico es realizado. Para el análisis y verificación por PCA de los espectros Raman, la hipótesis nula (Ho) se lee: “El espectro medido corresponde al set de entrenamiento usado para construir el modelo”. Un pequeño p-valor (<0,05) indica una evidencia fuerte en contra de Ho, y por lo tanto la hipótesis nula es rechazada y la muestra FALLA en pertenecer al modelo. Un gran p-valor resulta que la muestra PASA, indicando que la misma pertenece a la población del modelo, y p-valores superiores son aceptados con confianzas mayores. El PCA y los subsecuentes p-valores proveen una imagen muy diferente a la familia de ácidos grasos a compararlo con el análisis con HQI. La Tabla 2 indica infinitas distinciones entre los ácidos grasos.
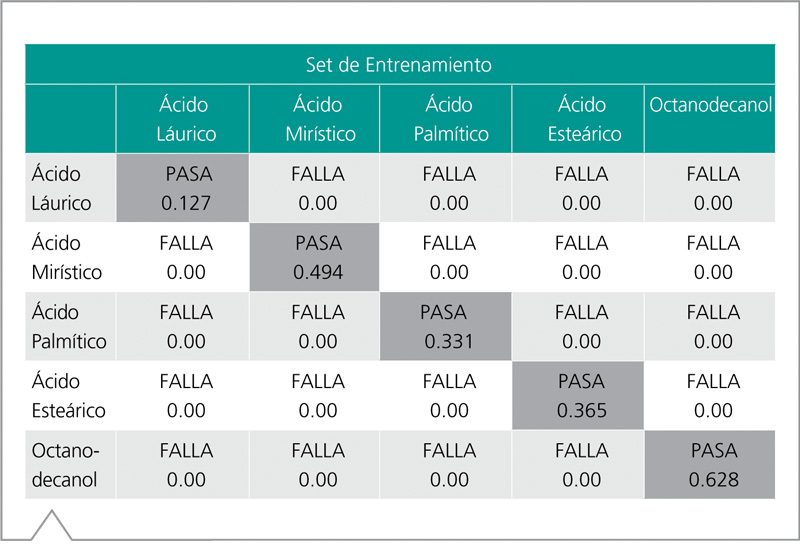
Tabla 2. P-valores y la validación de los resultados para la familia de ácidos grasos
Construyendo modelos a través de un set de entrenamiento
La efectividad del modelo PCA depende enteramente del set de entrenamiento, el cual es la librería de los espectros altamente correlacionados representados en la población del modelo. Haciendo uso del espectrofotómetro Raman Mira P y del software MiraCal, el usuario construye un set de entrenamiento colectando un mínimo de 20 espectros de una única sustancia con una cierta variación permitida.
Tipos de Varianza
La varianza en el set de entrenamiento es necesaria para crear un modelo robusto que represente apropiadamente la identidad de la muestra. Las variables pueden ser definidas como determinísticas, que son las fuentes conocidas de variación inherente a la identidad de la muestra o del instrumento. Las fuentes estocásticas o probabilísticas de la varianza incluyen factores experimentales que deben ser tenidos en cuenta para que no interfieran con la precisión del modelo en diferentes circunstancias5.
Fuentes de la varianza
La Varianza Determinística debe ser incluida en el set de entrenamiento para crear un modelo representativo. Por ejemplo, el usuario puede construir un set de entrenamiento usando muestras de múltiples fuentes. Si los parámetros específicos de adquisición del instrumento, como potencia del láser, temperatura, tiempo de integración, y número de scans, se van a usar en el experimento, el set de entrenamiento debe ser construido usándose esos mismos parámetros. Para mantener la consistencia del modelo, esos parámetros son almacenados como un Procedimiento Operativo para ser usados en futuras mediciones. Sin embargo, el set de entrenamiento debe ser construido durante varios días donde el equipo pase por varios ciclos de encendido y apagado para poder incorporar la variabilidad del instrumento.
La Varianza Estocástica debe ser incluida para crear un modelo que corrija variaciones aleatorias que pueden interferir en la verificación de la muestra. Estas son “condiciones de campo” como luz del ambiente y temperatura, material del contenedor, heterogeneidad de la muestra, tal vez incluso la variación en el espesor de un contenedor. Estas deben ser acomodadas para crear un set de entrenamiento robusto y continuo que mejore el nivel de confianza del p-valor reportado. Un resumen de las posibles fuentes de varianza se muestra en la Tabla 3.
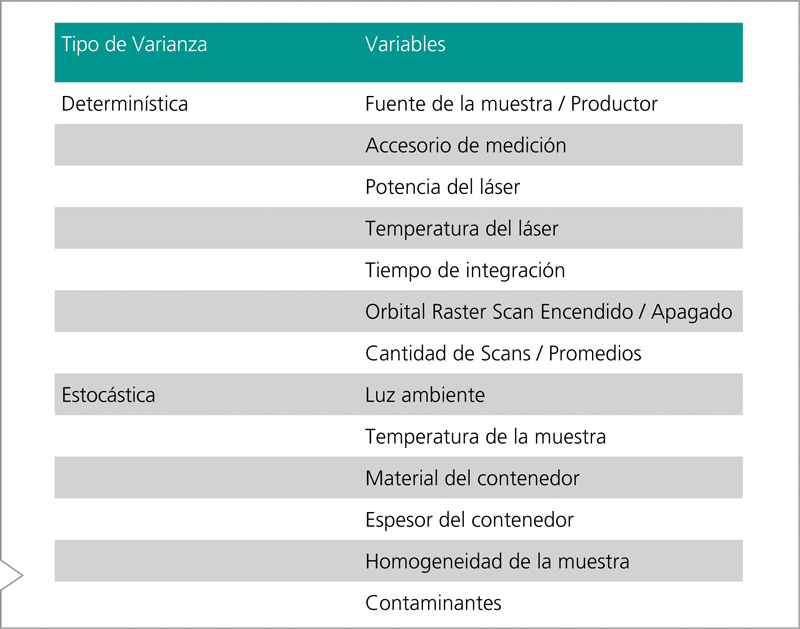
Tabla 3. Posibles tipos de varianza
Edición de un Set de Entrenamiento Robusto
Como recordatorio, un set de entrenamiento robusto incorpora cierta variación entre espectros, y debe también representar inherentemente la huella dactilar única del material de interés. Para asegurarse ambas de estas cualidades, una inspección visual de los espectros incluidos en un set de entrenamiento, seguidos de una edición cuidadosa pueden mejorar la verificación de los materiales con el Mira P. Un único espectro que obviamente es diferente a los otros del set puede ser removido, siempre y cuando se tomen los recaudos para dejar un nivel correcto de espectros representativos.
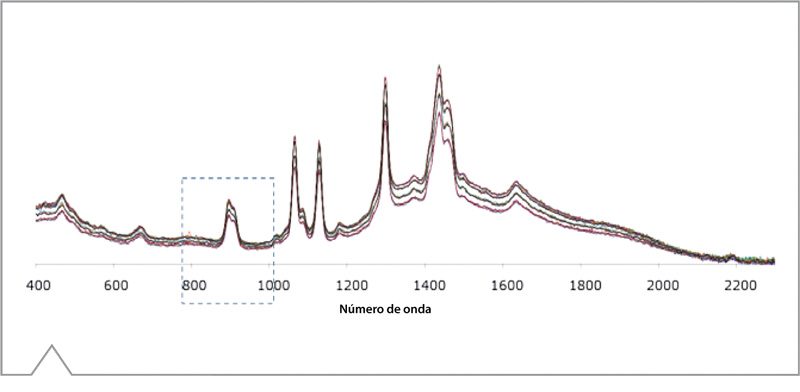
Figura 5. 20 espectros el Ácido Láurico.
La Figura 5 es un ejemplo de los espectros incluidos en el set de entrenamiento del ácido láurico, que fue usado para colectar la información descripta en las Tablas 1 y 2. Los 20 espectros fueron seleccionados de un total de 60, para una mejor visualización. Un nivel aceptable de varianza en intensidad (peso de los picos) puede ser vista, y esto representa la variación natural encontrada durante el curso del experimento. Si hacemos zoom dentro de la región delineada de la figura, podemos ver otro ejemplo de cómo estos espectros influyen en el set de entrenamiento. La línea vertical discontinua en la Figura 6 demuestra que el corrimiento en la alineación de los picos es consistente entre todos los espectros. Este es un ejemplo crucial de la información construida dentro del modelo de PCA, como los picos únicos en cualquier espectro Raman son la huella dactilar que hace que la misma sea una técnica de verificación tan sensible. A diferencia, las flechas indican varianzas aceptables encontradas durante el muestreo, las cuales son retenidas para un set de entrenamiento robusto.
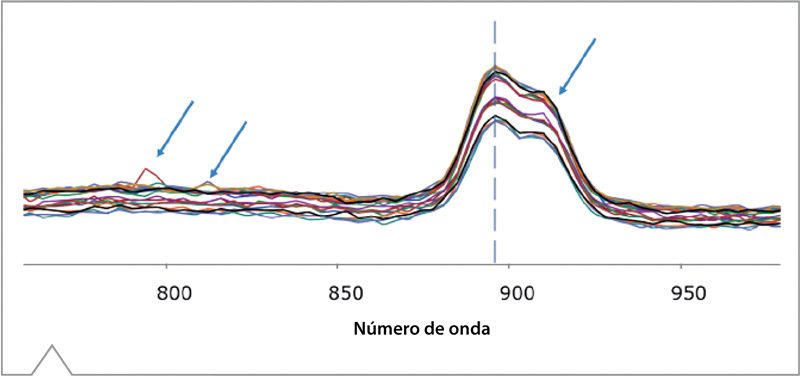
Figura 6. Zoom de los espectros del Ácido Láurico.
Conclusión
Esta publicación contrasta diferentes métodos de identificación y verificación para el espectrofotómetro portátil Mira P de Metrohm, los cuales son análisis distintivos para diferentes verificaciones. Las identificaciones son usadas cuando la identidad de una muestra es desconocida, y la verificación es usada para confirmar una muestra conocida. Esta publicación incluye las pautas necesarias para el usuario para construir un set de entrenamiento robusto que optimizará la precisión en la verificación el método.

Referencias







